Pourquoi la dérive dans l'apprentissage automatique peut détériorer les performances de votre modèle—et ce que vous pouvez faire à ce sujet
Pourquoi la dérive dans l'apprentissage automatique peut détériorer les performances de votre modèle—et ce que vous pouvez faire à ce sujet

Les modèles d'apprentissage automatique sont des outils puissants qui aident les organisations à prendre des décisions plus intelligentes. Cependant, avec le temps, la performance d'un modèle peut diminuer car les données sur lesquelles il a été formé ne reflètent plus les conditions actuelles. Ce phénomène est connu sous le nom de dérive. Dans cet article, nous expliquons la dérive dans l'apprentissage automatique, explorons les différents types et discutons de la façon dont les décideurs peuvent prendre des mesures simples pour maintenir la performance du modèle—même s'ils ne sont pas experts en science des données.
Les modèles d'apprentissage automatique sont des outils puissants qui aident les organisations à prendre des décisions plus intelligentes. Cependant, avec le temps, la performance d'un modèle peut diminuer car les données sur lesquelles il a été formé ne reflètent plus les conditions actuelles. Ce phénomène est connu sous le nom de dérive. Dans cet article, nous expliquons la dérive dans l'apprentissage automatique, explorons les différents types et discutons de la façon dont les décideurs peuvent prendre des mesures simples pour maintenir la performance du modèle—même s'ils ne sont pas experts en science des données.
Les modèles d'apprentissage automatique sont des outils puissants qui aident les organisations à prendre des décisions plus intelligentes. Cependant, avec le temps, la performance d'un modèle peut diminuer car les données sur lesquelles il a été formé ne reflètent plus les conditions actuelles. Ce phénomène est connu sous le nom de dérive. Dans cet article, nous expliquons la dérive dans l'apprentissage automatique, explorons les différents types et discutons de la façon dont les décideurs peuvent prendre des mesures simples pour maintenir la performance du modèle—même s'ils ne sont pas experts en science des données.
Qu'est-ce que la dérive en apprentissage automatique ?
La dérive en apprentissage automatique survient lorsqu’un modèle qui faisait auparavant des prédictions précises commence à mal fonctionner. Cela ne fait pas référence à des voitures dérivant sur un circuit ; cela décrit plutôt un changement au fil du temps dans l'environnement des données qui rend le modèle initial moins efficace. La dérive se produit lorsque les caractéristiques des données d'entrée changent ou lorsque la relation entre les données et le résultat cible évolue.
Pensez-y ainsi : Imaginez que vous ayez construit un modèle basé sur les données des clients de l’année dernière. Si vos données démographiques ou votre comportement d'achat changent cette année, le modèle pourrait ne pas prédire les tendances aussi précisément. Ce déclin de performance est dû à la dérive.
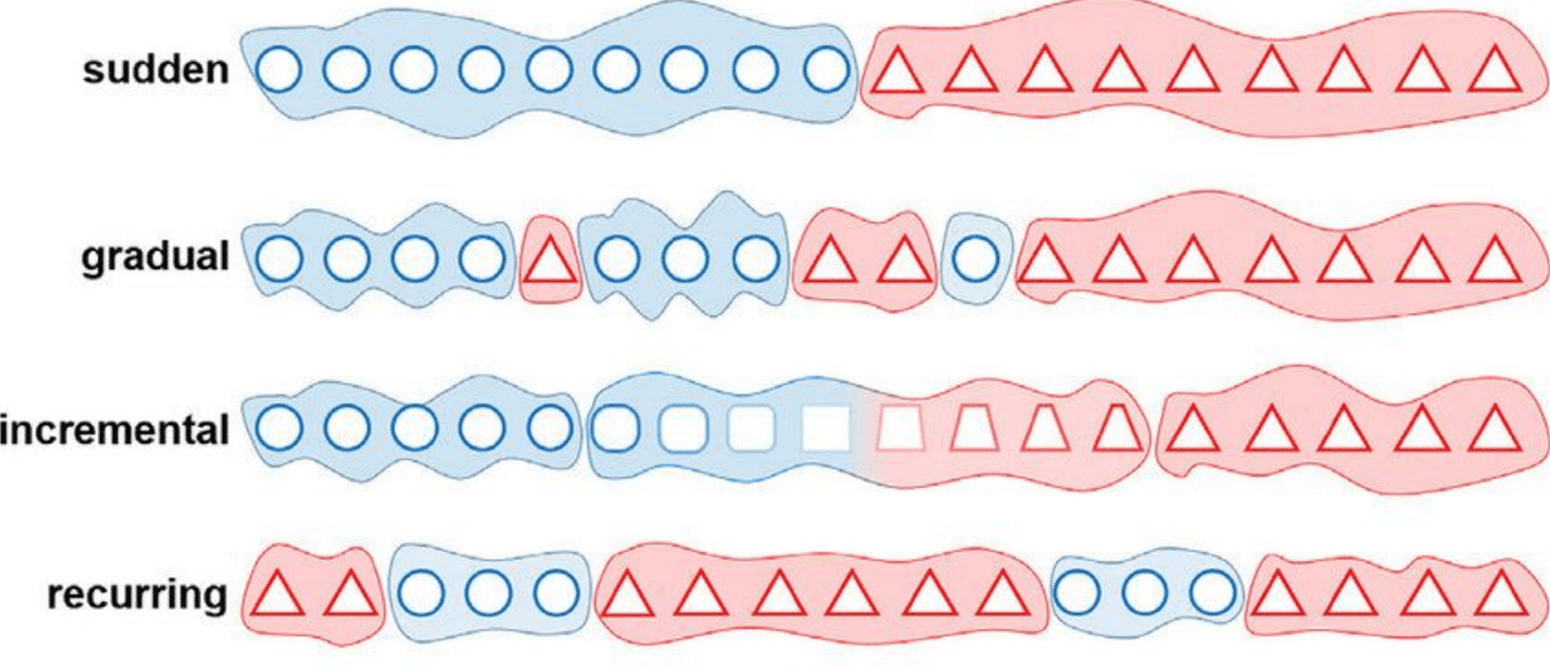
La dérive peut se manifester de plusieurs manières. Elle peut survenir soudainement, comme lorsqu'une nouvelle méthode de collecte de données est introduite, ou graduellement lorsque les motifs sous-jacents évoluent lentement. Parfois, la dérive suit un schéma récurrent, comme les changements saisonniers. Reconnaître la dérive tôt aide à prévenir des chutes significatives de performance.
Les quatre types de dérive
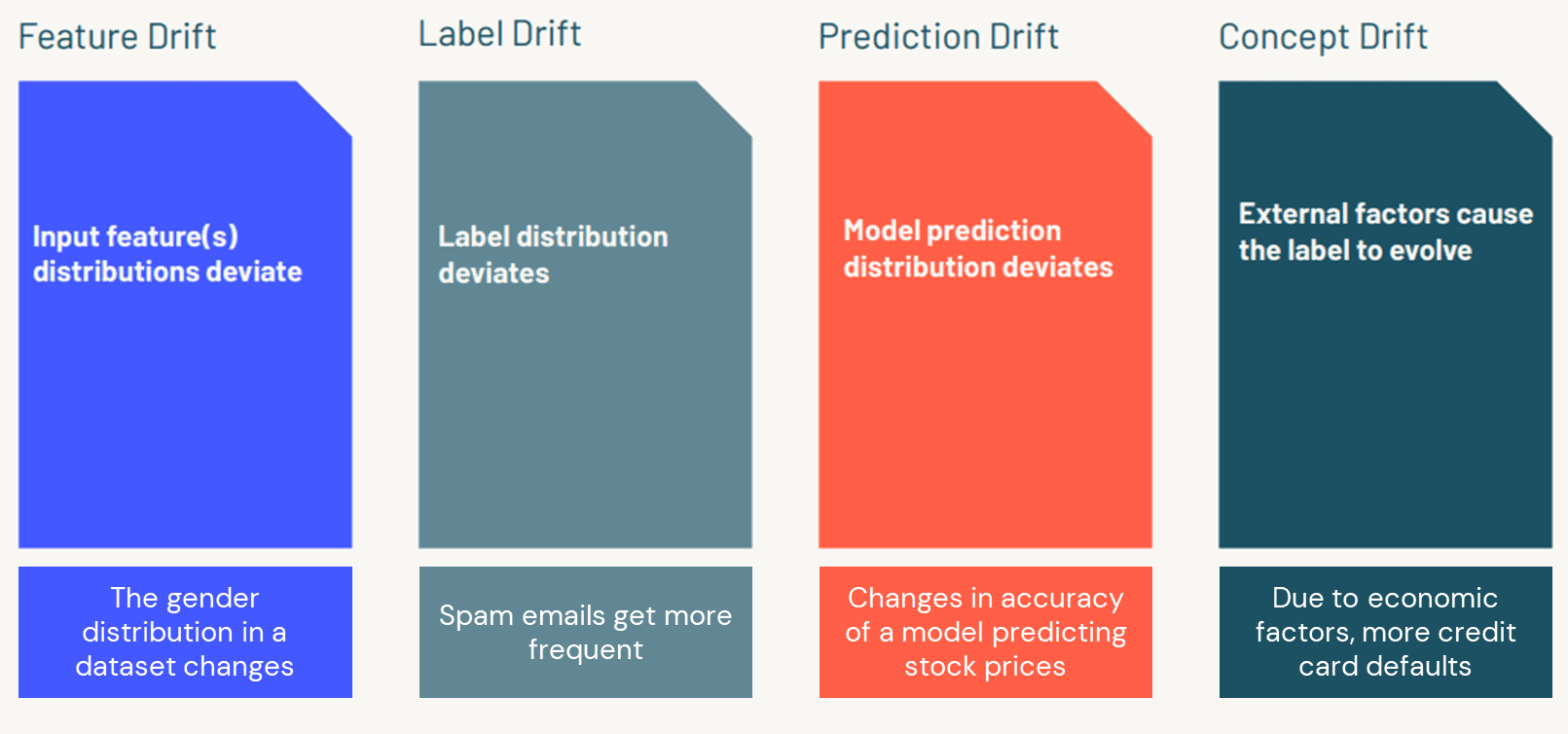
Comprendre le type spécifique de dérive qui affecte votre modèle est essentiel pour choisir la bonne contre-mesure. Dans notre discussion, nous nous concentrons sur quatre types : la dérive des caractéristiques, la dérive des étiquettes, la dérive des prédictions et la dérive conceptuelle.
1. Dérive des caractéristiques
La dérive des caractéristiques fait référence aux changements dans les variables d'entrée sur lesquelles votre modèle repose. Par exemple, imaginez que vos données d'origine contenaient principalement des sujets féminins. Au fil du temps, si vos données entrantes passent à des sujets majoritairement masculins, la distribution de vos caractéristiques change. Ce déplacement peut amener votre modèle à mal interpréter les données, réduisant finalement sa précision.
2. Dérive des étiquettes
La dérive des étiquettes se produit lorsque la distribution des résultats ou des étiquettes change. Considérez un modèle qui signale les e-mails spam. Si le pourcentage d'e-mails spam passe de 1 % à 10 %, un modèle entraîné sur des données avec un taux inférieur pourrait commencer à rater des signaux importants. Dans ce cas, les étiquettes (spam versus non-spam) ont changé, et le modèle doit être mis à jour.
3. Dérive des prédictions
La dérive des prédictions se produit lorsque les propres sorties du modèle commencent à montrer des tendances inattendues. Ce type de dérive peut survenir en raison d'une modification de la manière dont les données sont interprétées par le modèle. Par exemple, si un modèle qui prédisait auparavant une chance de 5 % pour un événement commence à prédire 10 % ou 15 % sans changement correspondant dans les données d'entrée, c'est probablement dû à la dérive des prédictions.
4. Dérive conceptuelle
La dérive conceptuelle se produit lorsque la relation sous-jacente entre les données d'entrée et le résultat change. Cette dérive est souvent due à des facteurs externes. Par exemple, lors d’un ralentissement économique, les facteurs déterminant les défauts de paiement sur les cartes de crédit peuvent changer radicalement. Même si les caractéristiques des données restent constantes, les prédictions du modèle peuvent souffrir car le concept lui-même a évolué.
Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=uPUrJ86GayUkI-p4&t=470
En décomposant la dérive en ces quatre types, vous pouvez identifier quelle partie de votre environnement de données a changé. Chaque type de dérive nécessite une approche légèrement différente pour y remédier.
Comment détecter et prévenir la dérive
Une fois que vous comprenez ce qu'est la dérive et les façons dont elle peut se manifester, l'étape suivante consiste à la détecter et à agir. La stratégie la plus courante consiste à réentraîner votre modèle en utilisant de nouvelles données reflétant les conditions actuelles. Cependant, savoir quand réentraîner est essentiel pour éviter des coûts inutiles ou des opportunités manquées.
Surveiller vos données
Vous pouvez surveiller la dérive en suivant des métriques clés qui révèlent des changements dans la distribution des données. Par exemple, en vérifiant les valeurs moyennes, les médianes ou même la répartition de vos données, vous pouvez voir si les variables d'entrée commencent à s'écarter de leurs schémas historiques. Des tests statistiques, tels que le test de Kolmogorov-Smirnov ou la divergence de Jensen-Shannon, peuvent également aider à quantifier ces changements.
Suivi des performances du modèle
Une autre méthode consiste à surveiller les métriques de performance du modèle. Des métriques comme la précision, l'aire sous la courbe (AUC) et l'erreur quadratique moyenne (RMSE) sont des indicateurs fiables de la santé de votre modèle. Si vous remarquez que ces métriques déclinent constamment, il est peut-être temps de réentraîner votre modèle.

Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=0Nhky3lK7WJae2n0&t=654
Utiliser des outils pour détecter la dérive
Les outils modernes simplifient la détection de la dérive. Un de ces outils est Evidently AI, une plateforme open-source qui offre des évaluations prédéfinies pour générer des rapports complets sur la dérive. Evidently AI peut produire des rapports HTML interactifs qui mettent en évidence la dérive à travers différents aspects de vos données, comme les distributions des caractéristiques et les métriques de performance.
Mieux encore, l'outil fournit des résultats structurés. Cela signifie que vous pouvez intégrer les résultats dans votre processus de travail. Lorsque la dérive atteint un certain seuil, vous pourriez automatiquement déclencher le réentraînement du modèle. Ce processus aide à garantir que vos modèles restent précis au fil du temps sans une surveillance manuelle constante.
Meilleures pratiques pour gérer la dérive
Définissez des seuils clairs : Décidez des métriques de performance qui comptent le plus pour votre entreprise. Fixez des seuils qui déclenchent un examen ou un processus de réentraînement lorsque ces métriques baissent.
Automatisez la surveillance : Dans la mesure du possible, automatisez le processus de surveillance des données et de performance. Des alertes automatisées peuvent vous aider à réagir rapidement avant que la dérive ne cause de sérieux problèmes.
Réentraîner si nécessaire : La règle d'or est de réentraîner votre modèle « lorsque vous en avez besoin ». Certains environnements changent lentement et peuvent nécessiter un réentraînement annuel. Dans des environnements rapides, le réentraînement pourrait être nécessaire plus fréquemment.
Utilisez des rapports visuels : Les tableaux de bord visuels et les rapports interactifs facilitent la compréhension des données pour les décideurs. Ils fournissent une vue claire de la survenance de la dérive, vous permettant d'agir rapidement.
Rassembler le tout
La dérive en apprentissage automatique constitue un défi réel, mais elle ne doit pas être un obstacle. En comprenant les types de dérive et en surveillant les indicateurs clés, vous pouvez maintenir vos modèles à leur meilleur niveau. Que vous choisissiez une surveillance manuelle ou que vous mettiez en place un processus automatisé, l’essentiel est de rester proactif et réactif.
Pour les décideurs, cela signifie qu'investir dans les bons outils et stratégies aujourd'hui peut faire économiser beaucoup de temps et de ressources demain. Pour les data scientists, cela souligne l'importance d'une approche proactive pour la gestion des modèles. La question n'est pas de savoir si votre modèle dérivera, mais quand. Vous devez être prêt à diagnostiquer et à actualiser quand cela est nécessaire pour minimiser les temps d'arrêt, les erreurs et les coûts.

Étapes suivantes
Si vous pensez que votre organisation pourrait bénéficier d'une surveillance améliorée de la dérive, envisagez de planifier un appel téléphonique avec notre équipe. Nous pouvons vous aider à examiner vos pratiques actuelles de gestion de modèle et à identifier les opportunités d'amélioration. Une simple discussion peut conduire à des gains significatifs en matière de performance des modèles et de résultats commerciaux.
Points clés à retenir
La dérive en apprentissage automatique se réfère à un déclin des performances des modèles au fil du temps dû à des changements dans les données ou les relations sous-jacentes.
Quatre types de dérive—dérive des caractéristiques, des étiquettes, des prédictions et conceptuelle—affectent les modèles de différentes manières.
Une détection précoce est cruciale. Surveillez à la fois vos données et les métriques de performance pour détecter la dérive avant qu'elle n'impacte votre entreprise.
Les outils comme Evidently AI aident à générer des rapports complets et permettent un réentrainement automatisé lorsque les performances baissent.
Le mot d'ordre est simple : Réentraînez uniquement lorsque cela est nécessaire pour équilibrer les améliorations de performance avec les considérations de coût.
En gardant ces principes à l'esprit, les organisations peuvent maintenir des modèles d’apprentissage automatique robustes qui s'adaptent aux environnements de données changeants. Cette approche proactive non seulement améliore l'exactitude des modèles, mais soutient également la planification stratégique à long terme.
Si vous avez des questions ou souhaitez explorer davantage les stratégies de gestion de la dérive, n'hésitez pas à nous contacter et à planifier un appel téléphonique avec nos experts. Nous sommes là pour vous aider à naviguer dans les défis du maintien de modèles d'apprentissage automatique performants.
Qu'est-ce que la dérive en apprentissage automatique ?
La dérive en apprentissage automatique survient lorsqu’un modèle qui faisait auparavant des prédictions précises commence à mal fonctionner. Cela ne fait pas référence à des voitures dérivant sur un circuit ; cela décrit plutôt un changement au fil du temps dans l'environnement des données qui rend le modèle initial moins efficace. La dérive se produit lorsque les caractéristiques des données d'entrée changent ou lorsque la relation entre les données et le résultat cible évolue.
Pensez-y ainsi : Imaginez que vous ayez construit un modèle basé sur les données des clients de l’année dernière. Si vos données démographiques ou votre comportement d'achat changent cette année, le modèle pourrait ne pas prédire les tendances aussi précisément. Ce déclin de performance est dû à la dérive.
La dérive peut se manifester de plusieurs manières. Elle peut survenir soudainement, comme lorsqu'une nouvelle méthode de collecte de données est introduite, ou graduellement lorsque les motifs sous-jacents évoluent lentement. Parfois, la dérive suit un schéma récurrent, comme les changements saisonniers. Reconnaître la dérive tôt aide à prévenir des chutes significatives de performance.
Les quatre types de dérive
Comprendre le type spécifique de dérive qui affecte votre modèle est essentiel pour choisir la bonne contre-mesure. Dans notre discussion, nous nous concentrons sur quatre types : la dérive des caractéristiques, la dérive des étiquettes, la dérive des prédictions et la dérive conceptuelle.
1. Dérive des caractéristiques
La dérive des caractéristiques fait référence aux changements dans les variables d'entrée sur lesquelles votre modèle repose. Par exemple, imaginez que vos données d'origine contenaient principalement des sujets féminins. Au fil du temps, si vos données entrantes passent à des sujets majoritairement masculins, la distribution de vos caractéristiques change. Ce déplacement peut amener votre modèle à mal interpréter les données, réduisant finalement sa précision.
2. Dérive des étiquettes
La dérive des étiquettes se produit lorsque la distribution des résultats ou des étiquettes change. Considérez un modèle qui signale les e-mails spam. Si le pourcentage d'e-mails spam passe de 1 % à 10 %, un modèle entraîné sur des données avec un taux inférieur pourrait commencer à rater des signaux importants. Dans ce cas, les étiquettes (spam versus non-spam) ont changé, et le modèle doit être mis à jour.
3. Dérive des prédictions
La dérive des prédictions se produit lorsque les propres sorties du modèle commencent à montrer des tendances inattendues. Ce type de dérive peut survenir en raison d'une modification de la manière dont les données sont interprétées par le modèle. Par exemple, si un modèle qui prédisait auparavant une chance de 5 % pour un événement commence à prédire 10 % ou 15 % sans changement correspondant dans les données d'entrée, c'est probablement dû à la dérive des prédictions.
4. Dérive conceptuelle
La dérive conceptuelle se produit lorsque la relation sous-jacente entre les données d'entrée et le résultat change. Cette dérive est souvent due à des facteurs externes. Par exemple, lors d’un ralentissement économique, les facteurs déterminant les défauts de paiement sur les cartes de crédit peuvent changer radicalement. Même si les caractéristiques des données restent constantes, les prédictions du modèle peuvent souffrir car le concept lui-même a évolué.
Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=uPUrJ86GayUkI-p4&t=470
En décomposant la dérive en ces quatre types, vous pouvez identifier quelle partie de votre environnement de données a changé. Chaque type de dérive nécessite une approche légèrement différente pour y remédier.
Comment détecter et prévenir la dérive
Une fois que vous comprenez ce qu'est la dérive et les façons dont elle peut se manifester, l'étape suivante consiste à la détecter et à agir. La stratégie la plus courante consiste à réentraîner votre modèle en utilisant de nouvelles données reflétant les conditions actuelles. Cependant, savoir quand réentraîner est essentiel pour éviter des coûts inutiles ou des opportunités manquées.
Surveiller vos données
Vous pouvez surveiller la dérive en suivant des métriques clés qui révèlent des changements dans la distribution des données. Par exemple, en vérifiant les valeurs moyennes, les médianes ou même la répartition de vos données, vous pouvez voir si les variables d'entrée commencent à s'écarter de leurs schémas historiques. Des tests statistiques, tels que le test de Kolmogorov-Smirnov ou la divergence de Jensen-Shannon, peuvent également aider à quantifier ces changements.
Suivi des performances du modèle
Une autre méthode consiste à surveiller les métriques de performance du modèle. Des métriques comme la précision, l'aire sous la courbe (AUC) et l'erreur quadratique moyenne (RMSE) sont des indicateurs fiables de la santé de votre modèle. Si vous remarquez que ces métriques déclinent constamment, il est peut-être temps de réentraîner votre modèle.
Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=0Nhky3lK7WJae2n0&t=654
Utiliser des outils pour détecter la dérive
Les outils modernes simplifient la détection de la dérive. Un de ces outils est Evidently AI, une plateforme open-source qui offre des évaluations prédéfinies pour générer des rapports complets sur la dérive. Evidently AI peut produire des rapports HTML interactifs qui mettent en évidence la dérive à travers différents aspects de vos données, comme les distributions des caractéristiques et les métriques de performance.
Mieux encore, l'outil fournit des résultats structurés. Cela signifie que vous pouvez intégrer les résultats dans votre processus de travail. Lorsque la dérive atteint un certain seuil, vous pourriez automatiquement déclencher le réentraînement du modèle. Ce processus aide à garantir que vos modèles restent précis au fil du temps sans une surveillance manuelle constante.
Meilleures pratiques pour gérer la dérive
Définissez des seuils clairs : Décidez des métriques de performance qui comptent le plus pour votre entreprise. Fixez des seuils qui déclenchent un examen ou un processus de réentraînement lorsque ces métriques baissent.
Automatisez la surveillance : Dans la mesure du possible, automatisez le processus de surveillance des données et de performance. Des alertes automatisées peuvent vous aider à réagir rapidement avant que la dérive ne cause de sérieux problèmes.
Réentraîner si nécessaire : La règle d'or est de réentraîner votre modèle « lorsque vous en avez besoin ». Certains environnements changent lentement et peuvent nécessiter un réentraînement annuel. Dans des environnements rapides, le réentraînement pourrait être nécessaire plus fréquemment.
Utilisez des rapports visuels : Les tableaux de bord visuels et les rapports interactifs facilitent la compréhension des données pour les décideurs. Ils fournissent une vue claire de la survenance de la dérive, vous permettant d'agir rapidement.
Rassembler le tout
La dérive en apprentissage automatique constitue un défi réel, mais elle ne doit pas être un obstacle. En comprenant les types de dérive et en surveillant les indicateurs clés, vous pouvez maintenir vos modèles à leur meilleur niveau. Que vous choisissiez une surveillance manuelle ou que vous mettiez en place un processus automatisé, l’essentiel est de rester proactif et réactif.
Pour les décideurs, cela signifie qu'investir dans les bons outils et stratégies aujourd'hui peut faire économiser beaucoup de temps et de ressources demain. Pour les data scientists, cela souligne l'importance d'une approche proactive pour la gestion des modèles. La question n'est pas de savoir si votre modèle dérivera, mais quand. Vous devez être prêt à diagnostiquer et à actualiser quand cela est nécessaire pour minimiser les temps d'arrêt, les erreurs et les coûts.
Étapes suivantes
Si vous pensez que votre organisation pourrait bénéficier d'une surveillance améliorée de la dérive, envisagez de planifier un appel téléphonique avec notre équipe. Nous pouvons vous aider à examiner vos pratiques actuelles de gestion de modèle et à identifier les opportunités d'amélioration. Une simple discussion peut conduire à des gains significatifs en matière de performance des modèles et de résultats commerciaux.
Points clés à retenir
La dérive en apprentissage automatique se réfère à un déclin des performances des modèles au fil du temps dû à des changements dans les données ou les relations sous-jacentes.
Quatre types de dérive—dérive des caractéristiques, des étiquettes, des prédictions et conceptuelle—affectent les modèles de différentes manières.
Une détection précoce est cruciale. Surveillez à la fois vos données et les métriques de performance pour détecter la dérive avant qu'elle n'impacte votre entreprise.
Les outils comme Evidently AI aident à générer des rapports complets et permettent un réentrainement automatisé lorsque les performances baissent.
Le mot d'ordre est simple : Réentraînez uniquement lorsque cela est nécessaire pour équilibrer les améliorations de performance avec les considérations de coût.
En gardant ces principes à l'esprit, les organisations peuvent maintenir des modèles d’apprentissage automatique robustes qui s'adaptent aux environnements de données changeants. Cette approche proactive non seulement améliore l'exactitude des modèles, mais soutient également la planification stratégique à long terme.
Si vous avez des questions ou souhaitez explorer davantage les stratégies de gestion de la dérive, n'hésitez pas à nous contacter et à planifier un appel téléphonique avec nos experts. Nous sommes là pour vous aider à naviguer dans les défis du maintien de modèles d'apprentissage automatique performants.
Qu'est-ce que la dérive en apprentissage automatique ?
La dérive en apprentissage automatique survient lorsqu’un modèle qui faisait auparavant des prédictions précises commence à mal fonctionner. Cela ne fait pas référence à des voitures dérivant sur un circuit ; cela décrit plutôt un changement au fil du temps dans l'environnement des données qui rend le modèle initial moins efficace. La dérive se produit lorsque les caractéristiques des données d'entrée changent ou lorsque la relation entre les données et le résultat cible évolue.
Pensez-y ainsi : Imaginez que vous ayez construit un modèle basé sur les données des clients de l’année dernière. Si vos données démographiques ou votre comportement d'achat changent cette année, le modèle pourrait ne pas prédire les tendances aussi précisément. Ce déclin de performance est dû à la dérive.
La dérive peut se manifester de plusieurs manières. Elle peut survenir soudainement, comme lorsqu'une nouvelle méthode de collecte de données est introduite, ou graduellement lorsque les motifs sous-jacents évoluent lentement. Parfois, la dérive suit un schéma récurrent, comme les changements saisonniers. Reconnaître la dérive tôt aide à prévenir des chutes significatives de performance.
Les quatre types de dérive
Comprendre le type spécifique de dérive qui affecte votre modèle est essentiel pour choisir la bonne contre-mesure. Dans notre discussion, nous nous concentrons sur quatre types : la dérive des caractéristiques, la dérive des étiquettes, la dérive des prédictions et la dérive conceptuelle.
1. Dérive des caractéristiques
La dérive des caractéristiques fait référence aux changements dans les variables d'entrée sur lesquelles votre modèle repose. Par exemple, imaginez que vos données d'origine contenaient principalement des sujets féminins. Au fil du temps, si vos données entrantes passent à des sujets majoritairement masculins, la distribution de vos caractéristiques change. Ce déplacement peut amener votre modèle à mal interpréter les données, réduisant finalement sa précision.
2. Dérive des étiquettes
La dérive des étiquettes se produit lorsque la distribution des résultats ou des étiquettes change. Considérez un modèle qui signale les e-mails spam. Si le pourcentage d'e-mails spam passe de 1 % à 10 %, un modèle entraîné sur des données avec un taux inférieur pourrait commencer à rater des signaux importants. Dans ce cas, les étiquettes (spam versus non-spam) ont changé, et le modèle doit être mis à jour.
3. Dérive des prédictions
La dérive des prédictions se produit lorsque les propres sorties du modèle commencent à montrer des tendances inattendues. Ce type de dérive peut survenir en raison d'une modification de la manière dont les données sont interprétées par le modèle. Par exemple, si un modèle qui prédisait auparavant une chance de 5 % pour un événement commence à prédire 10 % ou 15 % sans changement correspondant dans les données d'entrée, c'est probablement dû à la dérive des prédictions.
4. Dérive conceptuelle
La dérive conceptuelle se produit lorsque la relation sous-jacente entre les données d'entrée et le résultat change. Cette dérive est souvent due à des facteurs externes. Par exemple, lors d’un ralentissement économique, les facteurs déterminant les défauts de paiement sur les cartes de crédit peuvent changer radicalement. Même si les caractéristiques des données restent constantes, les prédictions du modèle peuvent souffrir car le concept lui-même a évolué.
Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=uPUrJ86GayUkI-p4&t=470
En décomposant la dérive en ces quatre types, vous pouvez identifier quelle partie de votre environnement de données a changé. Chaque type de dérive nécessite une approche légèrement différente pour y remédier.
Comment détecter et prévenir la dérive
Une fois que vous comprenez ce qu'est la dérive et les façons dont elle peut se manifester, l'étape suivante consiste à la détecter et à agir. La stratégie la plus courante consiste à réentraîner votre modèle en utilisant de nouvelles données reflétant les conditions actuelles. Cependant, savoir quand réentraîner est essentiel pour éviter des coûts inutiles ou des opportunités manquées.
Surveiller vos données
Vous pouvez surveiller la dérive en suivant des métriques clés qui révèlent des changements dans la distribution des données. Par exemple, en vérifiant les valeurs moyennes, les médianes ou même la répartition de vos données, vous pouvez voir si les variables d'entrée commencent à s'écarter de leurs schémas historiques. Des tests statistiques, tels que le test de Kolmogorov-Smirnov ou la divergence de Jensen-Shannon, peuvent également aider à quantifier ces changements.
Suivi des performances du modèle
Une autre méthode consiste à surveiller les métriques de performance du modèle. Des métriques comme la précision, l'aire sous la courbe (AUC) et l'erreur quadratique moyenne (RMSE) sont des indicateurs fiables de la santé de votre modèle. Si vous remarquez que ces métriques déclinent constamment, il est peut-être temps de réentraîner votre modèle.
Démo Databricks sur YouTube : https://youtu.be/tGckE83S-4s?si=0Nhky3lK7WJae2n0&t=654
Utiliser des outils pour détecter la dérive
Les outils modernes simplifient la détection de la dérive. Un de ces outils est Evidently AI, une plateforme open-source qui offre des évaluations prédéfinies pour générer des rapports complets sur la dérive. Evidently AI peut produire des rapports HTML interactifs qui mettent en évidence la dérive à travers différents aspects de vos données, comme les distributions des caractéristiques et les métriques de performance.
Mieux encore, l'outil fournit des résultats structurés. Cela signifie que vous pouvez intégrer les résultats dans votre processus de travail. Lorsque la dérive atteint un certain seuil, vous pourriez automatiquement déclencher le réentraînement du modèle. Ce processus aide à garantir que vos modèles restent précis au fil du temps sans une surveillance manuelle constante.
Meilleures pratiques pour gérer la dérive
Définissez des seuils clairs : Décidez des métriques de performance qui comptent le plus pour votre entreprise. Fixez des seuils qui déclenchent un examen ou un processus de réentraînement lorsque ces métriques baissent.
Automatisez la surveillance : Dans la mesure du possible, automatisez le processus de surveillance des données et de performance. Des alertes automatisées peuvent vous aider à réagir rapidement avant que la dérive ne cause de sérieux problèmes.
Réentraîner si nécessaire : La règle d'or est de réentraîner votre modèle « lorsque vous en avez besoin ». Certains environnements changent lentement et peuvent nécessiter un réentraînement annuel. Dans des environnements rapides, le réentraînement pourrait être nécessaire plus fréquemment.
Utilisez des rapports visuels : Les tableaux de bord visuels et les rapports interactifs facilitent la compréhension des données pour les décideurs. Ils fournissent une vue claire de la survenance de la dérive, vous permettant d'agir rapidement.
Rassembler le tout
La dérive en apprentissage automatique constitue un défi réel, mais elle ne doit pas être un obstacle. En comprenant les types de dérive et en surveillant les indicateurs clés, vous pouvez maintenir vos modèles à leur meilleur niveau. Que vous choisissiez une surveillance manuelle ou que vous mettiez en place un processus automatisé, l’essentiel est de rester proactif et réactif.
Pour les décideurs, cela signifie qu'investir dans les bons outils et stratégies aujourd'hui peut faire économiser beaucoup de temps et de ressources demain. Pour les data scientists, cela souligne l'importance d'une approche proactive pour la gestion des modèles. La question n'est pas de savoir si votre modèle dérivera, mais quand. Vous devez être prêt à diagnostiquer et à actualiser quand cela est nécessaire pour minimiser les temps d'arrêt, les erreurs et les coûts.
Étapes suivantes
Si vous pensez que votre organisation pourrait bénéficier d'une surveillance améliorée de la dérive, envisagez de planifier un appel téléphonique avec notre équipe. Nous pouvons vous aider à examiner vos pratiques actuelles de gestion de modèle et à identifier les opportunités d'amélioration. Une simple discussion peut conduire à des gains significatifs en matière de performance des modèles et de résultats commerciaux.
Points clés à retenir
La dérive en apprentissage automatique se réfère à un déclin des performances des modèles au fil du temps dû à des changements dans les données ou les relations sous-jacentes.
Quatre types de dérive—dérive des caractéristiques, des étiquettes, des prédictions et conceptuelle—affectent les modèles de différentes manières.
Une détection précoce est cruciale. Surveillez à la fois vos données et les métriques de performance pour détecter la dérive avant qu'elle n'impacte votre entreprise.
Les outils comme Evidently AI aident à générer des rapports complets et permettent un réentrainement automatisé lorsque les performances baissent.
Le mot d'ordre est simple : Réentraînez uniquement lorsque cela est nécessaire pour équilibrer les améliorations de performance avec les considérations de coût.
En gardant ces principes à l'esprit, les organisations peuvent maintenir des modèles d’apprentissage automatique robustes qui s'adaptent aux environnements de données changeants. Cette approche proactive non seulement améliore l'exactitude des modèles, mais soutient également la planification stratégique à long terme.
Si vous avez des questions ou souhaitez explorer davantage les stratégies de gestion de la dérive, n'hésitez pas à nous contacter et à planifier un appel téléphonique avec nos experts. Nous sommes là pour vous aider à naviguer dans les défis du maintien de modèles d'apprentissage automatique performants.
Prêt à atteindre vos objectifs avec les données ?
Si vous souhaitez atteindre vos objectifs grâce à une utilisation plus intelligente des données et de l'IA, vous êtes au bon endroit.
Prêt à atteindre vos objectifs avec les données ?
Si vous souhaitez atteindre vos objectifs grâce à une utilisation plus intelligente des données et de l'IA, vous êtes au bon endroit.
Prêt à atteindre vos objectifs avec les données ?
Si vous souhaitez atteindre vos objectifs grâce à une utilisation plus intelligente des données et de l'IA, vous êtes au bon endroit.
Prêt à atteindre vos objectifs avec les données ?
Si vous souhaitez atteindre vos objectifs grâce à une utilisation plus intelligente des données et de l'IA, vous êtes au bon endroit.